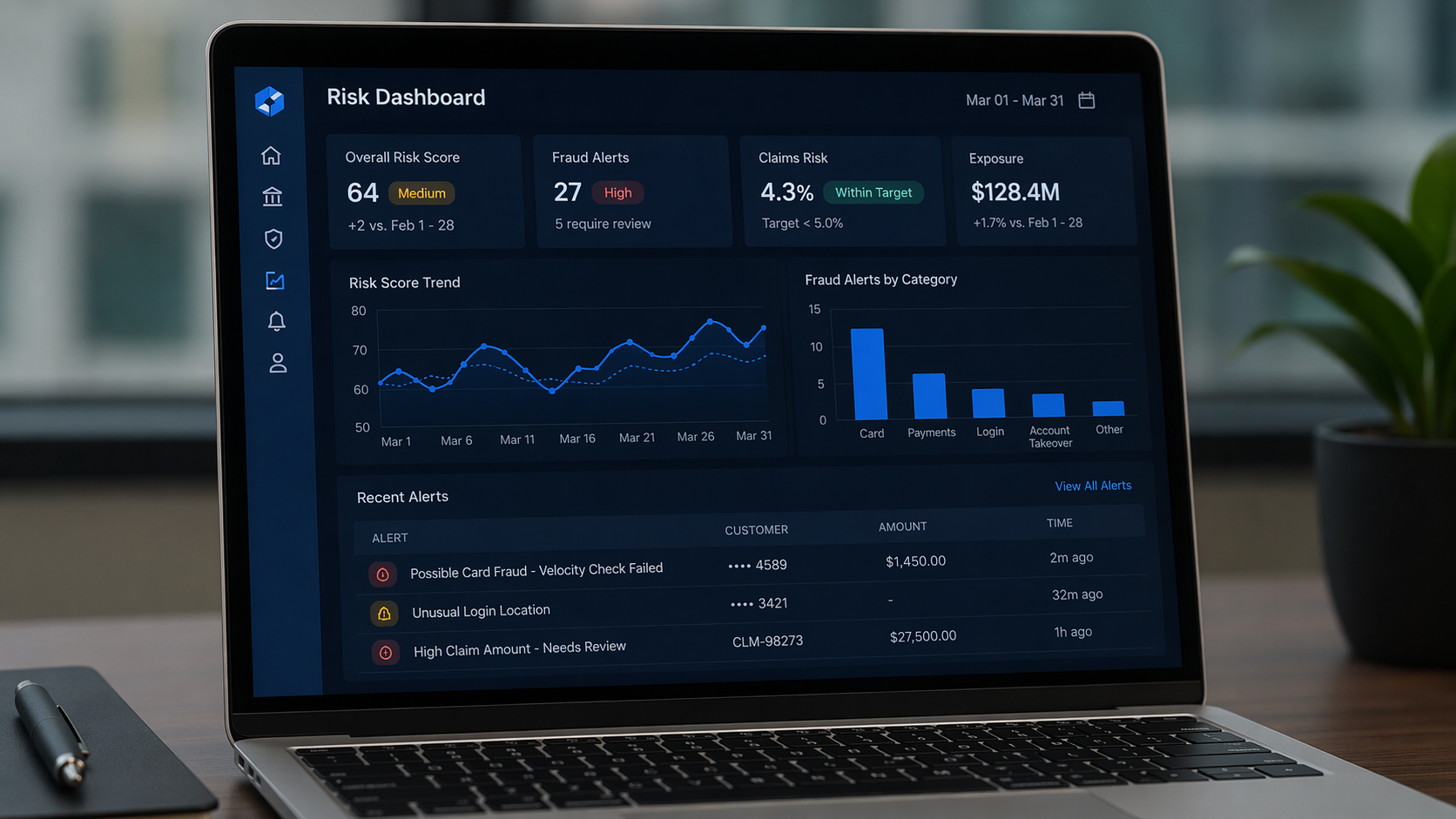
From Synthetic Data to a Live Risk Dashboard
RiskSight Pro is structured as a single Flask application with a shared dark-theme shell injected into every page. On startup, three ML models are trained in memory on 5,200+ synthetic records covering credit borrowers, fraud transactions, insurance policies, and one year of daily market returns. Every chart is a server-side Plotly figure serialised to JSON and rendered client-side — no static images, no stale data.
Seven Risk Modules in One App
Three Production-Style Models + Statistical Risk Engine
Each model is trained at application startup using Scikit-learn on in-memory synthetic data, then serialised via a StandardScaler pipeline. The REST API endpoints receive JSON from browser forms and return scored results in milliseconds — the same pattern used in real-world risk systems.
Simulated Risk Outputs by Module
Select a risk module below to see representative outputs. These illustrate what the live app returns for typical inputs.
Illustrative outputs based on synthetic data patterns in the app. Live app scores inputs in real time via trained ML models.
Risk Metrics Across the Synthetic Portfolio
Grade F borrowers show ~4× the default rate of Grade A. The Random Forest feature importance highlights credit score and debt ratio as the two dominant predictors.
ATM and online channels carry the highest fraud rates — consistent with card-not-present and skimming patterns. Night-hour (0–5h) transactions account for a disproportionate share of fraud flags.
All three policy tiers sit above the break-even LR of 1.0 when the 25% expense ratio is added — illustrating the underwriting risk challenge the platform is designed to surface.
Three Engineering Choices That Define the App
app.py. HuggingFace Spaces needs only a Dockerfile and requirements.txt.random_state=42. This keeps the deployment artefact-free while ensuring reproducible, deterministic outputs every time.Plotly.react() — ensuring charts are responsive, interactive, and theme-aware without extra round-trips.