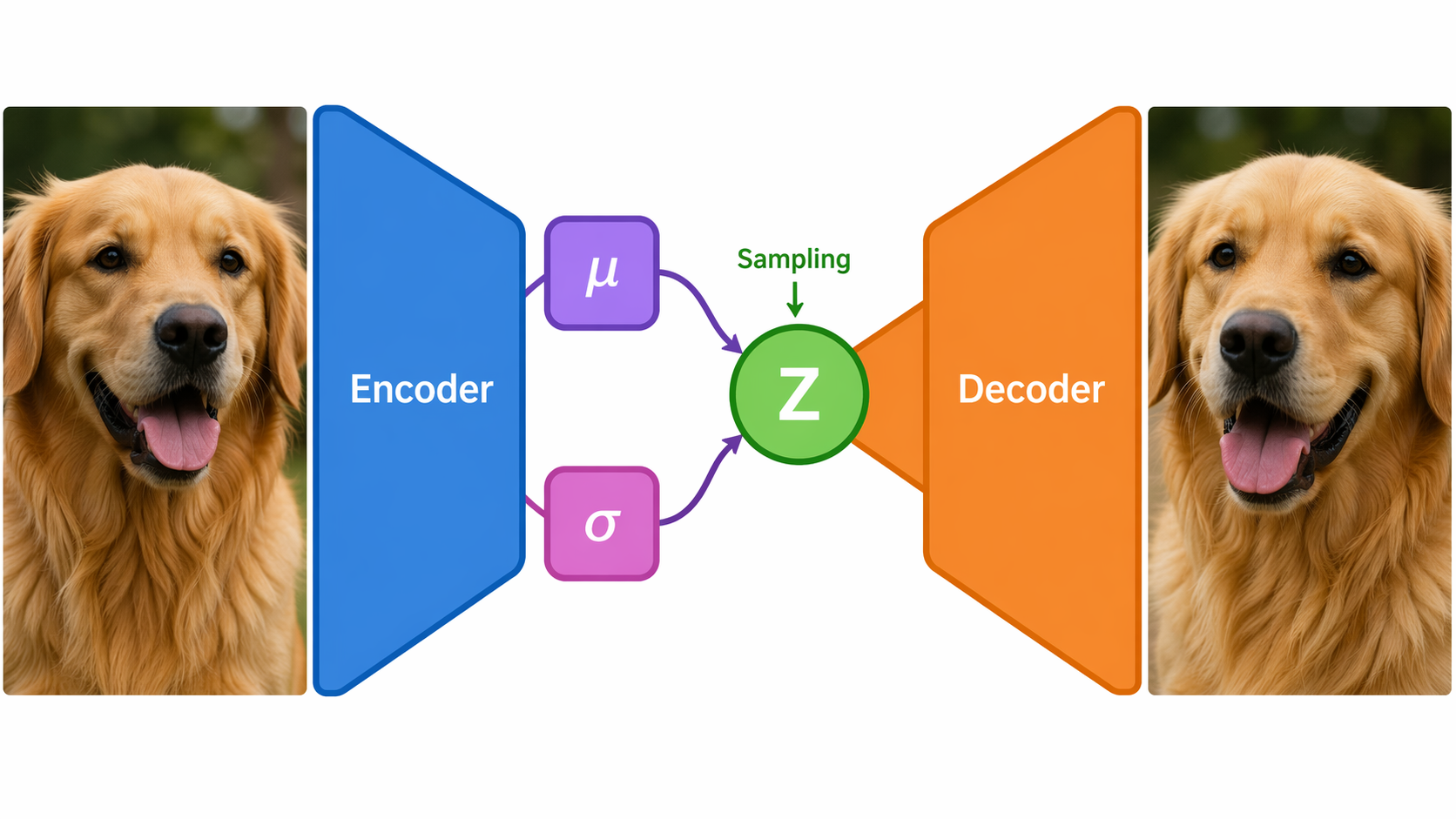
From Pixel to Latent Point and Back
A VAE learns to compress each 28×28 MNIST digit into a two-number coordinate in "latent space", then reconstruct the original from that coordinate. Because the latent space is regularised to be smooth and Gaussian, you can pick any coordinate — even one never seen during training — and the decoder will generate a plausible-looking digit. This page lets you watch every step of that process unfold in real time.
Five Interactive Tabs, One Unified Playground
VAE Layer Diagram & Loss Decomposition
ELBO Loss (Evidence Lower Bound)
ℒ = ℒ_recon + KL
Reconstruction (Binary Cross-Entropy, sum)
ℒ_recon = −Σ [ x·log x̂ + (1−x)·log(1−x̂) ]
KL Divergence (closed-form Gaussian)
KL = −½ Σ [ 1 + log σ² − μ² − σ² ]
Configurable Hyperparameters
| Parameter | Default |
|---|---|
| Epochs | 30 |
| Batch size | 128 |
| Learning rate | 1e-3 (Adam) |
| Hidden dim (H) | 400 |
| Latent dim (L) | 2 |
Visualise VAE Concepts Without Running the App
Select a view below to see illustrative examples of what each tab in the live app produces after training.
Each cell represents a region of the 2-D latent space. After training, digits of the same class cluster together — the VAE has learned to organise the latent manifold semantically.
Stylised representation of the 2-D latent space; colour encodes digit class (0–9).
Top row: original MNIST samples. Bottom row: VAE reconstructions decoded from the 2-D latent code. Slight blurriness is expected — BCE loss smooths pixel predictions toward the mean.
Illustrative reconstruction comparison. Live app uses actual PyTorch model outputs.
In the live app, two sliders control Z₁ and Z₂ (each from −3 to +3). The decoder maps that coordinate to a digit image in real time. Moving across the manifold smoothly interpolates between digit classes.
Five sample (Z₁, Z₂) coordinates and their decoded digit representation. The live app lets you explore any point with sliders.
Expected Training Behaviour
Typical ELBO loss over 30 epochs on the 10,000-sample MNIST subset with LR=1e-3 and hidden dim=400. Loss drops sharply in early epochs as the decoder learns basic digit structure, then flattens as fine detail is refined.
Approximate fraction of digit classes that form visually distinct latent clusters, measured by inter-cluster distance. Most classes separate by epoch 10; digits 4/9 and 3/5 remain closest due to visual similarity.
Trade-off between reconstruction quality (lower BCE = better) and latent interpretability as latent dimension increases from 2 to 20. The 2-D default is chosen to maximise visual interpretability at a small quality cost.
Three Engineering Choices That Define This App