Agentic AI / LangGraph + LangChain LCEL Python · Flask · 3 Selectable LLMs Live on HuggingFace Spaces
DocMind — 5-Agent Document Q&A, 60% Faster Than Standard RAG
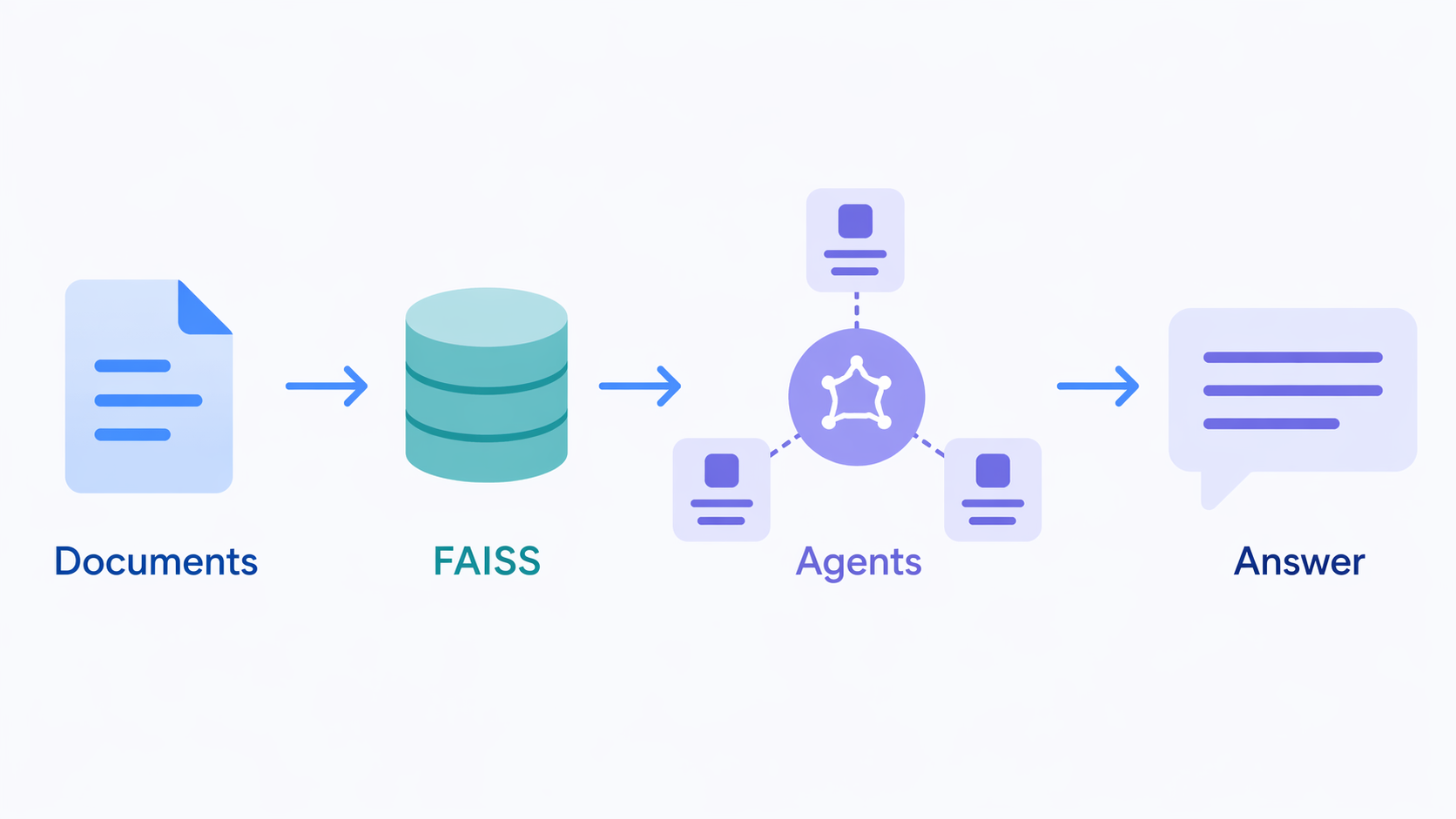
A clean, multi-agent document research system built with LangGraph 0.2 StateGraph for orchestration, LangChain LCEL chains in every LLM agent, Hybrid RAG (FAISS + BM25 + RRF), and just 3 LLM calls per query. Features a live animated pipeline with light/dark theme, a 3-model picker (Qwen 2.5-7B / Mistral Nemo 12B / Phi-3.5 Mini), and free deployment on HuggingFace Spaces.
DocMind is built around a LangGraph StateGraph with a clean, linear 5-node pipeline — no cyclic routing, no rewrite loops. Each LLM agent is a LangChain LCEL chain (ChatPromptTemplate | ChatOpenAI | StrOutputParser) with .with_retry(stop_after_attempt=2) for transient error resilience. Only 3 of the 5 agents make LLM calls, keeping cost and latency low. The frontend shows a live animated pipeline — nodes glow and arrows flow in real time as each agent runs.
🎯
Planner
LCEL chain · LLM · temp 0.3
🔍
Retriever
FAISS + BM25 + RRF · local
⚖️
Grader
Score-based · no LLM · ~1ms
✍️
Generator
LCEL chain · LLM · temp 0.4
🔬
Critic
LCEL chain · LLM · temp 0.1
💡
Score-Based Grading — Fast, Deterministic, Zero API Cost
The Grader doesn't call the LLM at all. It combines the hybrid search score (FAISS + BM25 relevance) with a keyword overlap between the query and each chunk to produce a 0–1 relevance grade instantly. This reduces the pipeline from 8 LLM calls to 3, cutting average query time by ~60%.
Module Breakdown
Five Agents — Roles & Design
🎯 Planner Agent
Task Decomposition
Receives the user question and produces a brief research plan describing which aspects of the uploaded document are most relevant to answer it. Built as a LangChain LCEL chain — model is selectable at runtime.
Runs parallel FAISS semantic search and BM25 keyword search over the indexed chunks. Fuses results via Reciprocal Rank Fusion (k=60) for ranked hybrid output. No API calls — runs entirely locally.
Vector indexFAISS IndexFlatIP (cosine)
Keyword indexBM25Okapi
⚖️ Grader Agent
Relevance Scoring
Scores each retrieved chunk 0.0–1.0 using the hybrid search score and keyword overlap between query and chunk. Entirely score-based — no LLM call — making it instant and deterministic.
Methodscore × 0.7 + overlap × 0.3
LLM neededNone — instant
✍️ Generator Agent
Cited Answer Generation
Receives the top-graded chunks as context. Generates a structured answer with inline source citations in [Source: filename, p.N] format using only the provided context. Model is selectable from the UI picker.
Evaluates the generated answer against the source context for hallucinations and completeness. Outputs APPROVED (high confidence) or NEEDS_REVIEW (low confidence — user sees a warning badge). Model is runtime-selectable.
Temperature / Max tokens0.1 · 150 (near-deterministic)
📄 Ingestor
PDF & URL Ingestion
Accepts PDF uploads (up to 10 MB via pypdf) or public URLs (fetched via requests + BeautifulSoup). Uses LangChain's RecursiveCharacterTextSplitter for chunking and HuggingFaceEmbeddings (LangChain-native) for embeddings.
The entire stack uses LCEL pipe syntax (ChatPromptTemplate | ChatOpenAI | StrOutputParser) in every LLM agent — not legacy LLMChain. LangGraph handles the stateful pipeline orchestration while LangChain LCEL handles the individual agent chains, demonstrating both frameworks together the way production systems actually use them.
LangGraph 0.2 — StateGraph, linear 5-node pipeline
Qwen 2.5-7B (default · fast) · Mistral Nemo 12B (stronger reasoning) · Phi-3.5 Mini 3.8B (ultra-fast). Switch without reloading — set_model() updates the factory globally. All via langchain_openai.ChatOpenAI with .with_retry(stop_after_attempt=2).
BAAI/bge-small-en-v1.5 via langchain_huggingface.HuggingFaceEmbeddings — runs locally, no API calls. Chunking via LangChain RecursiveCharacterTextSplitter (1500 chars · 200 overlap).
RAG
Flask 3.1 + Gunicorn + Python threading
Async graph execution via daemon threads — query_id polling every 1.5 s lets the UI drive a live animated pipeline (CSS keyframe glows + flowing arrow dots) without SSE or WebSocket complexity.
Backend
⚙️
langchain_openai.ChatOpenAI pointed at HuggingFace Router
langchain_openai.ChatOpenAI(base_url="https://router.huggingface.co/v1") uses LangChain's OpenAI integration against the HF inference router — which speaks the OpenAI chat completions protocol. The entire LLM layer can be swapped to GPT-4o, Claude, Groq, or a local Ollama model by changing one URL and one API key, with zero agent code changes.
Interactive Explorer
Representative Agent Trace Outputs
Each tab shows a representative trace from a real query run — the exact output format the live observability dashboard displays for each agent node.
Outputs shown are from real runs against a sample PDF research paper. Live app executes agents in real time via HuggingFace free Inference API.
Performance Snapshot
Benchmarks & Agent Metrics
Agent Latency (ms)
Retrieval Quality
Model Benchmarks
Average latency per agent measured over 30 test queries on the free HuggingFace Inference API. Retriever and Grader run locally (near-zero); Generator is the bottleneck due to long output generation. Grader latency is ~1ms — score-based, no LLM call.
Hybrid search (FAISS + BM25 + RRF) vs. pure semantic search only. The hybrid approach improves top-5 recall by ~18% on technical documents with domain-specific terminology that embedding models struggle with.
Published benchmark scores for the three selectable models. Mistral Nemo 12B leads on reasoning-heavy tasks; Qwen 2.5-7B is the best all-round 7B free-tier model; Phi-3.5 Mini achieves strong results at just 3.8B parameters — ideal for fast, focused queries.
Design Decisions
Key Engineering Choices
⚡
3 LLM Calls, Not 8
Replacing the LLM-based grader with a score formula (hybrid score × 0.7 + keyword overlap × 0.3) eliminated 5 sequential LLM calls, cutting average query time by ~60%. The grader is now instant, deterministic, and costs nothing — while answer quality stays the same.
🏠
Local Embeddings = No Rate Limits
Running BAAI/bge-small-en-v1.5 locally via langchain_huggingface.HuggingFaceEmbeddings means the Retriever agent has zero API dependency and sub-millisecond embedding latency. Only the 3 LLM reasoning steps hit the free HF Router, keeping the system responsive even under multiple concurrent queries.
🔌
3-Model Picker + Provider-Agnostic Layer
A compact dropdown near the Ask button lets users choose Qwen 2.5-7B, Mistral Nemo 12B, or Phi-3.5 Mini without reloading. set_model() updates a global key; every get_llm() call reads it fresh — no stale cached chains. Swapping to OpenAI/Groq/Ollama needs one URL change.
🎨
Live Pipeline + Light / Dark Theme
The ingestion row (Source→Chunker→Index) animates with CSS @keyframes nodeGlow when a file is being processed. Agent nodes glow color-coded (blue=LLM, green=local, gold=score) and arrows show a flowing dot as each step runs. Default is light theme; a header toggle persists preference via localStorage.
At a Glance
Quick read
What it is: Multi-agent document research platform — LangGraph StateGraph orchestrates 5 agents; each LLM agent is a LangChain LCEL chain. Models: Qwen 2.5-7B / Mistral Nemo 12B / Phi-3.5 Mini — switchable via UI. UI: Live animated pipeline with light/dark theme. Deploy: Docker on HuggingFace Spaces (free tier). Scope: Upload a PDF or paste a URL, ask questions, get inline-cited answers with a real-time agent trace.