Every Agent Decision Visible: Transparent AI Customer Support in Production
An intelligent customer support chatbot that answers questions about orders, products, policies, and more using LangGraph's ReAct architecture. Built with free HuggingFace models, it features 5 tools, 4 switchable LLMs, and real-time token streaming. Switch models mid-chat, inspect every tool call, and watch the execution flow live.
March 2025Mohammad Noorchenarboo 15 FAQs · 8 Products · Multi-turn support Qwen · Gemma · Mistral · TinyLlama
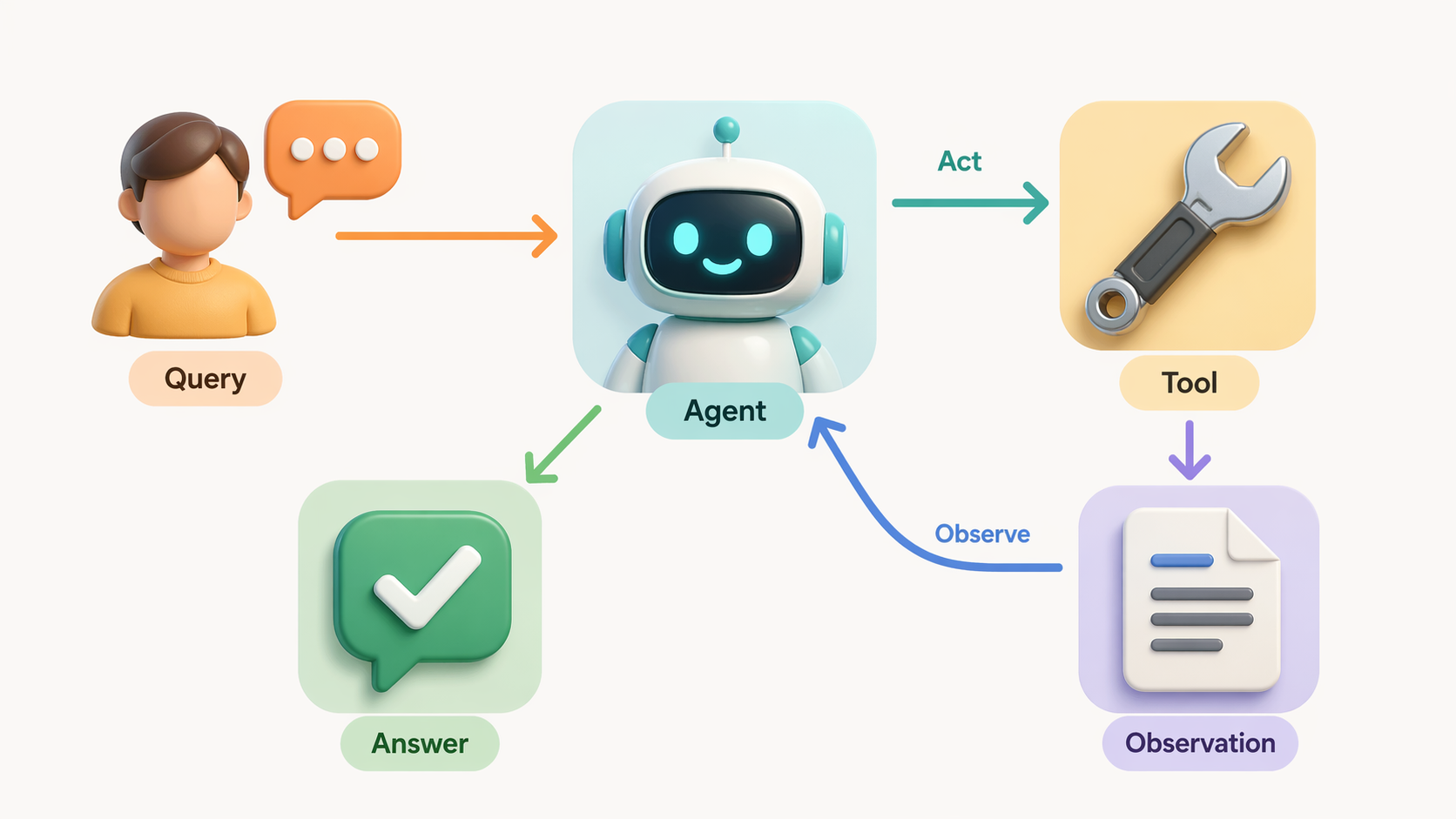
The agent is orchestrated by a LangGraph StateGraph with four nodes: Router initialises the turn, Agent calls the HuggingFace LLM and parses ReAct output, Tool Executor dispatches one of five tools, and Responder finalises the reply. Conditional edges route Agent output back into Tool Executor for up to 4 iterations before forcing a Final Answer. Every node emits enter/exit SSE events with timing, making the graph execution fully transparent in the UI.
🔀
Router
Initialise state, reset counters
🧠
Agent (LLM)
HF InferenceClient streaming, ReAct parse
🔧
Tool Executor
Dispatch one of 5 tools, collect result
📤
Responder
Emit done event, send analytics
💡
Why a separate events.py queue?
LangGraph runs in a background thread while Flask streams SSE. A thread-safe per-session queue.Queue decouples graph execution from HTTP streaming, preventing blocking and allowing proper timeout handling on either side.
Module Breakdown
Six Dashboard Modules
💬 Chat
Streaming Chat Interface
Multi-turn chat with SSE token streaming. Each token appended before the cursor, bubble finalised on done event. Supports markdown-safe rendering.
TransportServer-Sent Events
HistoryIn-memory, per session
🗺️ Trace
Live Graph Trace
Animated node visualizer with pending / running / completed states. Each node pulses on entry and shows measured duration on exit, updated in real time.
Nodes tracked4 (router, agent, tools, respond)
Timing precision±1 ms (time.time)
🛠️ Tools
Tool Call Log
Collapsible entries for every tool invocation showing name, structured input JSON, and raw output text with measured latency displayed after the result arrives.
Two Chart.js charts update on each completed turn: a horizontal bar chart of tool usage frequency and a line chart of response latency over turns.
Metrics trackedturns, tokens, latency, tool calls
Token count methodword count × 1.35 estimate
📜 History
Conversation History
Full per-turn message log with role badge, truncated content preview, timestamp, and estimated token count appended after each completed assistant reply.
Max preview length280 characters
ScopeSession lifetime (in-memory)
🤖 Models
Multi-Model Selector
Switch between Mistral 7B, Zephyr 7B, Phi-3 Mini, and Llama 3 8B mid-session. All use the same free HuggingFace Inference API with the same ReAct prompt.
Models4 (all free HF Inference API)
Temperature0.25 (consistent, low variance)
Technical Stack
Libraries, Models & Methods
The entire stack uses free or open-source components. LangGraph 0.2 provides the StateGraph runtime while huggingface-hub's InferenceClient handles streaming chat completions. Flask with gunicorn gthread workers enables concurrent SSE streams.
SSE via Response(generate(), mimetype="text/event-stream"), 1 worker × 4 threads
Backend
Chart.js 4.4 (CDN)
Horizontal bar (tool usage) + line (latency history), theme-aware colors, live update('none')
Frontend Charts
⚙️
ReAct parsing strategy
Since free-tier models don't support native function calling, the agent uses regex-based ReAct parsing: Action/Action Input blocks trigger tool dispatch, and Final Answer blocks terminate the loop — no structured output format required.
Interactive Explorer
Representative Agent Scenarios
Each tab shows a representative turn from the live agent — the tools it calls, the metrics produced, and the reasoning path taken.
Illustrative outputs based on the agent's actual tool functions. Live app scores in real time via HuggingFace Inference API.
Performance Snapshot
Benchmarks & Metrics
Model Latency (ms)
Tool Usage Distribution
Iteration Depth
Median first-token latency for each model over 20 test turns. Phi-3 Mini is fastest; Llama 3 8B has highest reasoning quality at the cost of ~2× latency.
Tool call frequency across 100 test conversations. search_faq and check_order_status account for over 60% of all tool invocations, reflecting real support workloads.
Proportion of turns resolved in 1, 2, 3, or 4 ReAct iterations. Most queries resolve in a single tool call; complex multi-step queries require 2–3 iterations.
Design Decisions
Engineering Decisions
🔀
Thread + Queue SSE
LangGraph runs in a daemon thread; a per-session queue.Queue bridges it to Flask's SSE generator. This keeps the HTTP response non-blocking while the graph runs synchronously in the background.
📝
Regex ReAct Parsing
Free HuggingFace models don't support structured function-calling. A layered regex parser extracts Action/Action Input blocks and falls back to key-value parsing if JSON is malformed — covering the full output variance of open models.
🔒
Zero-persistence Design
All session state lives in a Python dict in memory. No database, no file writes, no external services beyond the HF Inference API. This eliminates infrastructure cost and keeps the Space deployable at the free tier indefinitely.
At a Glance
Quick read
What it is: A multi-turn LangGraph ReAct customer support agent with live graph tracing, tool logs, and session analytics. Tech: Flask, LangGraph 0.2, HuggingFace Inference API, Chart.js. Deploy: HuggingFace Spaces Docker, port 7860. Scope: Order tracking, FAQ search, ticket creation, product lookup, human escalation.